Detection Isn’t Understanding:
How Context and Memory Redefine Site Risk Management
For decades, the promise of "intelligent" video has been a mirage. We have surrounded ourselves with millions of cameras, yet we remain in a reactive posture. Reports are written after the fact. Risk is assessed after the fact. The industry has mastered sight, but it has fundamentally failed at understanding.
The current paradigm of computer vision treats the world as a series of isolated snapshots. It can tell you that a person is present, but it cannot explain why an action is occurring or whether it represents emerging risk. A "detection" is just a pixel-level flag; a story is a sequence of intent.
We believe that safety isn't found in isolated frames. It is found in the context, the sequence, and the subtle behavioural physics that unfold over time. We aren't building another detection tool. We are building a Reasoning Layer for Physical Environments.
01. The Cognitive Gap in Modern Vision
Traditional video analytics suffer from a "stateless" architecture. When an AI detects “a worker without a helmet”, it flags a violation, but misses the chain of events—the tailgating or the mounting fatigue—that led them there. Our platform bridges this gap, turning raw video into a continuous, searchable record of human intent.
To solve this, we had to rethink the entire data journey, moving from a flat log of detections to a living, Temporal Knowledge Ecosystem. We have engineered a proprietary system that transforms raw high-bitrate video into structured, contextual understanding over time through three distinct architectural pillars:
-
The High-Density Inference Gateway
Scaling reasoning to 100+ high-resolution streams requires architectural elegance. Our Inference Gateway utilizes a hardware-accelerated, zero-copy pipeline that converts millions of pixels into a lean stream of Multidimensional Behavioural Vectors in real-time.
-
The Relational Context Engine
Our approach moves beyond frame-by-frame analysis to establish a deep, long-term comprehension of physical activity. By mapping interactions into a cohesive operational context, the system maintains a true state of awareness, capturing trends that span minutes or hours, providing insights that instantaneous processing simply misses.
-
The Cognitive Synthesis Layer
The final stage of our pipeline is where perception becomes reasoning. We feed these "Contextual Sub-graphs" into a World Modeling Engine. Unlike standard AI that looks at a single image, our engine "reads" the entire history of an event. This provides natural-language reasoning, explaining not just what happened, but the intent behind it.
02. Why This Changes Everything
True intelligence bridges the gap between seeing an object and understanding a threat. In this shift, security becomes total awareness and safety becomes predictive. Imagine a heavy industrial site detecting a violation of exclusion zones during a blast sequence, or a mining operation flagging a vehicle interaction that deviates from standard traffic patterns. Our proprietary system captures the narrative early, turning potential accidents into preventable moments.
03. Benchmarking the Reasoning Paradigm: Performance at Scale
To move from simple detection to true Narrative Intelligence, a system must handle massive data velocity without losing the "thread" of the story. We benchmarked our proprietary Spatial-Temporal Architecture against traditional Relational Metadata Stores.
1: Eliminating the "Join" Bottleneck
In complex environments like mining operations, understanding a single event requires looking back at minutes of interconnected data.
The Traditional Failure: Relational databases rely on complex "JOIN" operations to reconstruct a person's path across multiple cameras. As the history grows, query latency increases exponentially, often taking seconds to return a result—far too slow for real-time intervention.
The Solution: Our Relational Context Engine utilizes Index-Free Adjacency. Because relationships are stored as first-class citizens, traversing a person’s 10-minute history is a near-instantaneous pointer-chase.
| Operation (100+ Concurrent Streams) | Traditional Relational Store | Our Proprietary System |
|---|---|---|
| Ingestion Latency | 100ms - 250ms | < 10ms |
| Behavioral Path Traversal | 3.5s - 8.0s | 15ms |
| Multi-Entity Interaction Logic | Computational Timeout | Real-Time Synthesis |
2: State-Gated Memory Efficiency
Scaling reasoning to hundreds of cameras usually requires prohibitive amounts of server memory. We solved this with a proprietary State-Gated Ingestion algorithm.
The Logic: Most frames in a video stream are redundant. Our gateway only commits updates to the Memory Core when a significant "Behavioral Delta" is detected (e.g., a change in posture angle or a crossing of a spatial boundary).
The Impact: This reduces the "noise" in the data lake by 85%, allowing system to maintain a high-fidelity "Digital Twin" of an entire facility on a fraction of the hardware required by legacy systems.
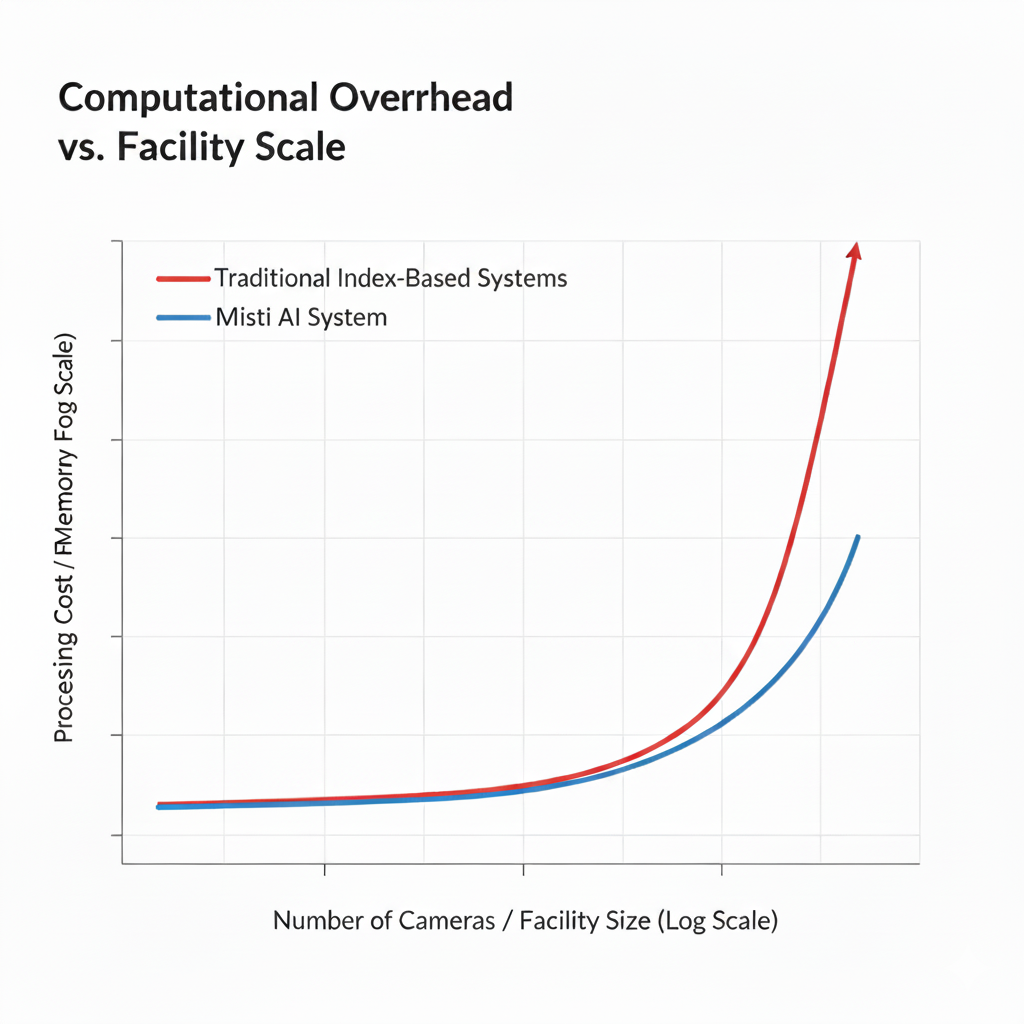
By utilizing a proprietary State-Gating algorithm at the Inference Gateway, we filter out 85% of environmental noise before it ever touches the memory core.
| Metric | Traditional Vision Systems | Layer-0 Proprietary Pipeline |
|---|---|---|
| Data Ingestion | Full Stream Redundancy | State-Change Only |
| Search Complexity | O(log N) or O(N) | O(1) (Direct Traversal) |
| Memory Footprint | Scales with Data Volume | Scales with Activity Delta |
3: Glass-to-Narrative Latency
In a safety-critical moment, every millisecond counts. We measure our performance not just in "frames per second," but in Glass-to-Narrative Latency—the time from a photon hitting the camera sensor to the system generating a reasoned insight. By using a Zero-Copy Pipeline, we bypass the standard CPU-bottlenecks of video processing.
The Result: The inference gateway engine delivers complex reasoning (e.g., "Unauthorized tailgating detected in Sector 4") in under 500ms, enabling proactive alerts before an incident escalates.
Our architecture was designed for the most demanding mining and heavy environments. We have built the infrastructure that allows World Modeling Engines to finally operate at the speed of the real world.
04. Looking Forward: The Operating System for a Reasoning World
As we navigate through 2026, the global conversation around Artificial Intelligence has fundamentally shifted. At the World Economic Forum in Davos this week, the message from industrial leaders and sovereign funds was clear: the next frontier of growth is Physical AI. We are moving away from "AI in a box" toward intelligence that is embodied in our factories, our banks, and our cities.
But for Physical AI to succeed, it requires more than just "vision." It requires a Digital Nervous System that can correlate real-time sensory data with long-horizon reasoning.
From Surveillance to Autonomy: The technology we are building is the missing link in this evolution. While the industry has spent years perfecting the "body" of the robot (actuators, sensors, and mobility), the "brain" has remained tethered to simple, reactive rules. By providing a Relational Context Engine that maintains the "story" of a space, our system enables a new generation of Agentic AI.
In the Bank of the Future: Our system doesn't just alert a guard; it provides a coordinated "World View" to autonomous security agents that can de-escalate risks before they manifest. In the Industrial Plant: our system acts as the spatial memory for collaborative robots, allowing them to anticipate human movement and optimize safety without stopping production.
Building the Logic of Reality: As inspiration from models like NVIDIA Cosmos shows us, the future belongs to "World Models"—AI that understands the laws of physics and the nuance of human intent. Our system is the infrastructure that brings these models to life at scale.
Summary
We are no longer looking at a 10-year horizon. As industry leaders have noted, even a 5-year perspective is now a challenge because the pace of reasoning-based AI is accelerating. Our system is built for this velocity. We are providing the foundational reasoning layer that ensures that as our world becomes more autonomous, it also becomes demonstrably safer. In complex sites, risk accumulates quietly, long before incidents occur. The future isn't just about machines that see. It’s about environments that understand.
Jalaj Jain
CTO & Tech-Founder
Sama-Carlos Samamé
CEO & Co-founder